


しばしば一覧画面で一覧されている要素に紐づく最新の何かも表示したくなることがあります。例えば、ブログサイトの記事一覧の記事に対する最新のコメントなどです。こういった時の高速化の方法を一つ紹介します
例えば、次の情報と関係があるとします。
- 記事
- 記事ID、題名、本文、投稿日時
- コメント
- コメントID、コメントした記事のID、コメント内容、コメント日時
ブログっぽいものの想定です。これを元に正規化と元々の関係性を重視してテーブルとリレーションを作ると次のようになります。
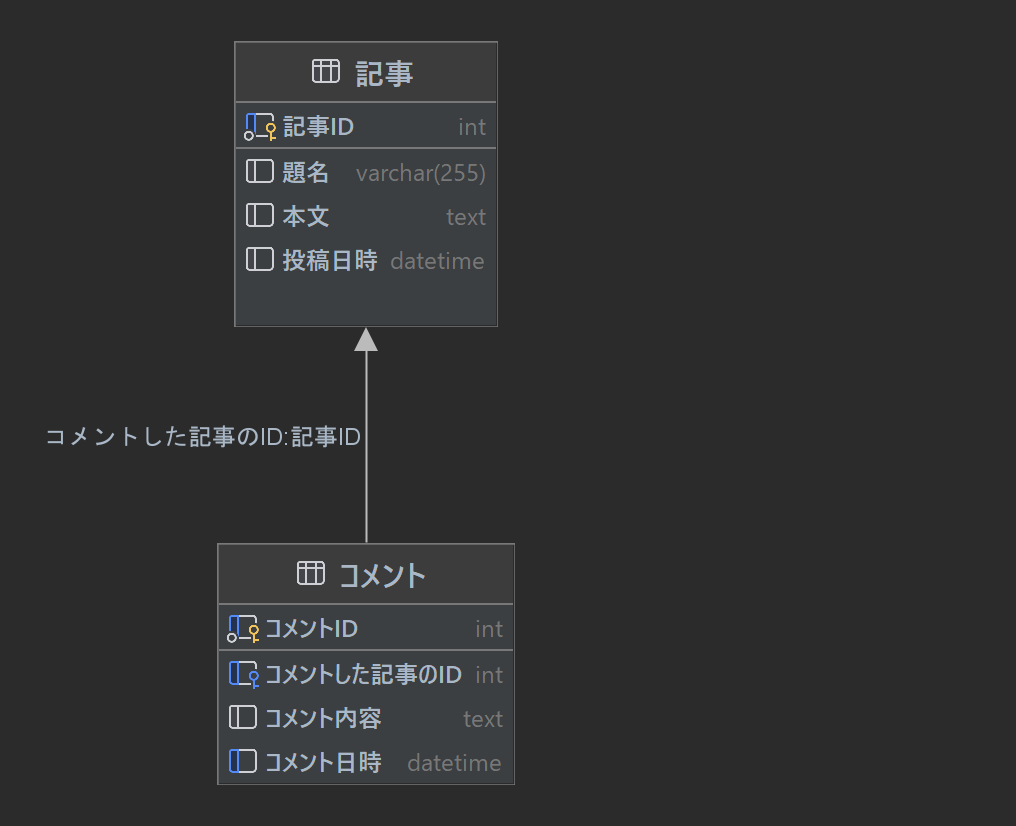
分かりやすい構造です。実際にSQLにすると次のようになります。
例のテーブルとテストデータを作るSQL
CREATE TABLE 記事
(
記事ID INT PRIMARY KEY AUTO_INCREMENT,
題名 VARCHAR(255),
本文 TEXT,
投稿日時 DATETIME
);
CREATE TABLE コメント
(
コメントID INT PRIMARY KEY AUTO_INCREMENT,
コメントした記事のID INT,
コメント内容 TEXT,
コメント日時 DATETIME,
FOREIGN KEY (コメントした記事のID) REFERENCES 記事 (記事ID)
);
INSERT INTO 記事 (題名, 本文, 投稿日時)
VALUES ('記事のタイトル1', 'これはテストの記事の本文です。', '2024-01-08 10:00:00'),
('記事のタイトル2', 'これは別のテスト記事の本文です。', '2024-01-08 11:00:00'),
('記事のタイトル3', 'さらに別のテスト記事の本文です。', '2024-01-08 12:00:00');
INSERT INTO コメント (コメントした記事のID, コメント内容, コメント日時)
VALUES (1, 'これは記事1に対するコメントです。', '2024-01-08 11:00:00'),
(2, 'これは記事2に対するコメントです。', '2024-01-08 11:00:00'),
(2, 'これは記事2に対する別のコメントです。', '2024-01-08 11::30:00'),
(3, 'これは記事3に対するコメントです。', '2024-01-08 12:30:00');
この状態で次の情報が表示される検索画面が追加されるとします。
- 題名
- 投稿日時
- 最新コメント
- 最新コメント日時
こうなると最近コメントされた順で記事を検索するSQLは例えば次のようになります。
SELECT
題名,
投稿日時,
最新コメントの内容,
最新コメント日時
FROM 記事
LEFT JOIN (
SELECT
コメントした記事のID,
コメント内容 AS 最新コメントの内容,
コメント日時 AS 最新コメント日時
FROM コメント
WHERE コメントID IN (SELECT MAX(コメントID) FROM コメント GROUP BY コメントした記事のID)
) AS コメント ON 記事.記事ID = コメント.コメントした記事のID
ORDER BY 最新コメント日時 DESC
LIMIT 30;
記事を約19万件、コメントを約70万件用意した時このSQLのEXPLAIN結果は次のようになります。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | 記事 | null | ALL | null | null | null | null | 172905 | 100 | Using temporary; Using filesort |
| 1 | PRIMARY | コメント | null | ref | コメントした記事のID | コメントした記事のID | 5 | tmp.記事.記事ID | 3 | 100 | Using where |
| 3 | SUBQUERY | コメント | null | range | コメントした記事のID | コメントした記事のID | 5 | null | 175778 | 100 | Using index for group-by |
このSQLは遅いSQLです。特にサブクエリの結果をJOINする部分とJOINした後の並び替えが遅いです。どちらもインデックスによる事前計算ができないため、ここまでのデータベースの構造のままではいかんともしがたいです。コメント内容が表示対象に含まれてなければコメントをFROMにしてGROUP BY コメントした記事のIDでごにょごにょすることもできますが、それもできません。
こういった背景から高速化のために正規化を崩して「最新コメントID」カラムを記事テーブル側に追加し、それを活用する方法を取ることがあります。テーブル定義を更新すると次のようになります。
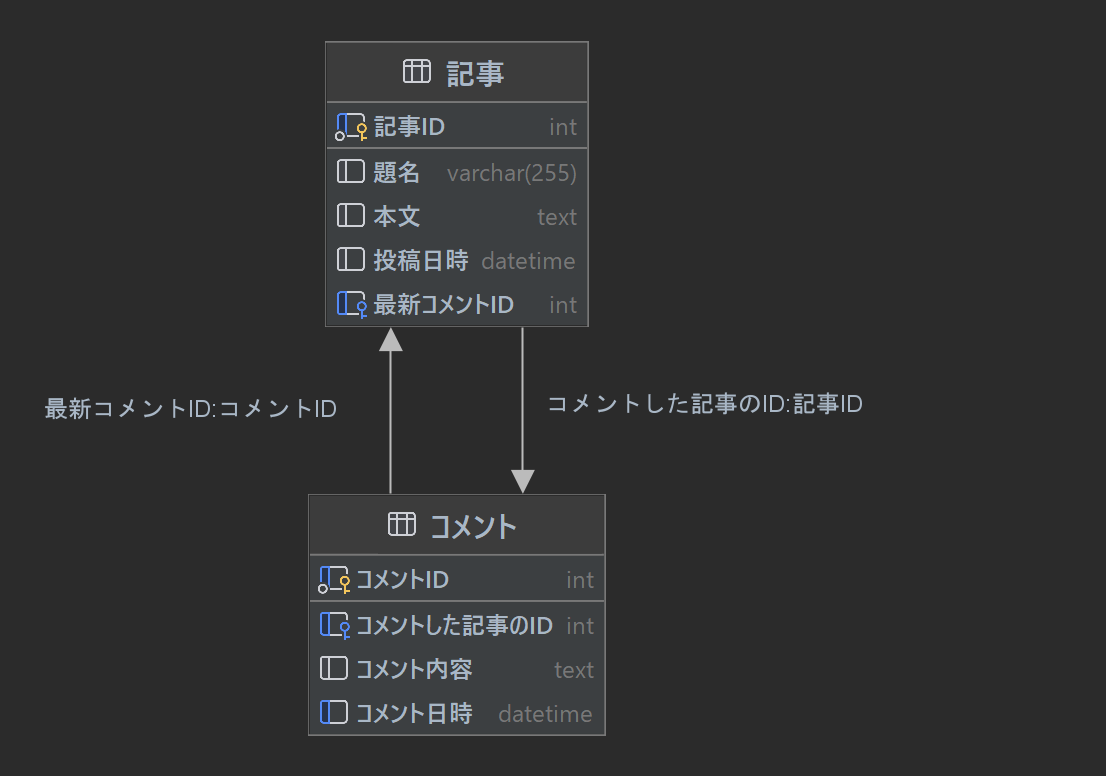
この変更後のテーブルにあるべきデータを反映するSQLは次のようになります。
UPDATE 記事
SET 最新コメントID = (
SELECT コメントID
FROM コメント
WHERE コメント.コメントした記事のID = 記事.記事ID
ORDER BY コメント日時 DESC
LIMIT 1
);
カラムに入れたい情報をSQLで取得して、それをSETしてUPDATEする感じです。一度これを実行したらデータベースを使うプログラム内で都度更新されるようにロジックを埋め込むのがおすすめです。
最新コメントIDカラムが増えたら次のようにSQLを使って最近コメントされた順で記事を取得できます。
EXPLAIN SELECT
題名,
投稿日時,
コメント内容 AS 最新コメントの内容,
コメント日時 AS 最新コメント日時
FROM 記事
LEFT JOIN コメント ON 記事.最新コメントID = コメント.コメントID
ORDER BY 最新コメントID DESC
LIMIT 30;
EXPLAIN結果も次のようになり、インデックスを使ってごく狭い範囲をパパっと探していることがわかります。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | 記事 | null | index | null | 記事_コメント_コメントID_fk | 5 | null | 30 | 100 | Backward index scan |
| 1 | SIMPLE | コメント | null | eq_ref | PRIMARY | PRIMARY | 4 | tmp.記事.最新コメントID | 1 | 100 | null |
正規化を崩すとデータの整合性の面で危うさが増えますが、それ以上に利便性が増すのであれば正規化を崩すこともあります。この記事では最新の情報についての例を挙げましたが他にも子テーブルの中から特定の一つのレコードを抜き出して何かをするような時には同じようなことができます。

