

Unicode(ユニコード)は、符号化文字集合や文字符号化方式などを定めた、文字コードの業界規格である。文字集合(文字セット)が単一の大規模文字セットであること(「Uni」という名はそれに由来する)などが特徴である。
引用:Unicode – Wikipedia
この引用文にある通り、Unicodeは非常に多くの文字を含んだ文字コードです。多種多様な文字を扱うために文字に分類付けがされています。この分類の仕方は複数あり、この記事で扱う分類はスクリプトです。スクリプトは文字体系による分類形式です。Script (Unicode) – Wikipediaにはスクリプトの一覧が載っています。
正規表現ではUnicodeプロパティを用いて文字を識別できます。日本語のスクリプト名はそれぞれ、ひらがながHiragana、カタカナがKatakana、漢字がHanと名付けられています。ちなみにこのHanは繁体字のHanです。
例えばjavascriptでは次の画像の様にUnicodeプロパティを用いた正規表現を使えます。
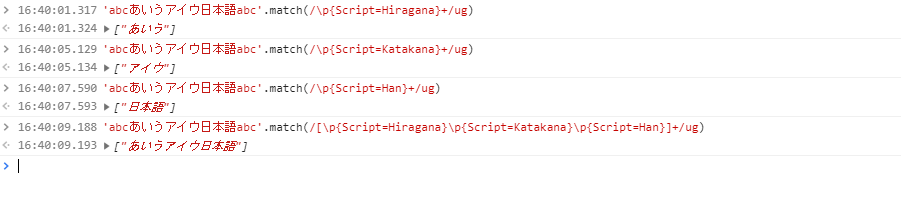
/\p{分類の名前=分類の中における文字集合の名前}/u
phpなら
$pattern = '/\p{Hiragana}/u';
javascriptにもphpにもついていたuはUnicodeを使うという宣言です。
import regex
pattern = r'\p{Han}'
print(regex.findall(pattern, "朝早く起きた"))
pythonはとてもシンプルな記法です。ただし3系の正規表現でもデフォルトではUnicodeプロパティ表現に対応しておらず、regex · PyPIのようなライブラリが必要です。
注意点としてUnicodeのプロパティによる分類は強力ですが、Unicodeという探索範囲がとても広いため速度はあまり優秀でありません。PHPのPHP: Unicode 文字プロパティ – Manual にも以下の様に注意書きがあります。
Unicode プロパティを使った文字列マッチングは速くありません。PCRE は 15,000 以上のデータからなるストラクチャを検索する必要が有るためです。 そのため、PCRE では、\d や \w といった 以前から有るエスケープシーケンスは Unicode プロパティを使用しないように なっています。

