BudouX は Google 製の機械学習結果を元にした日本語の区切りを発見するためのライブラリです。これを使って何がうれしいかというと文字列の折り返しタイミングを自然にできます。
Google が用意してくれているデモは次です。これの中で適当な意味の通った文章を用意し、画像の様に Replace WBR with BR をチェックすると何をしてくれているか分かりやすいです。
BudouX demo
実際に使ったデモとソースコードが次です。文字列をいい感じに区切って配列化してくれています。
import "./styles.css";
// 日本語のパーサーを呼び出す関数をインポート
import { loadDefaultJapaneseParser } from "budoux";
// 日本語パーサーを生成
const parser = loadDefaultJapaneseParser();
// 日本語の文字列を生成したパーサーに食わせると
// いい感じに配列化してくれます
const msg = `BudouX は Google 製の機械学習結果を元にした日本語の区切りを発見するためのライブラリです。これを使って何がうれしいかというと文字列の折り返しタイミングを自然にできます。`;
const parsed = parser.parse(msg);
// パース結果を表示
document.getElementById("app").innerHTML = `
<pre>
${JSON.stringify(parsed, null, 2)}
</pre>
`;
使い方は上記ソースコードの通りで簡易です。パーサーを用意した後は文字列を渡すだけでいい感じにしてくれます。配列にしたら隙間に<wbr>タグを入れるか、それぞれを span タグでくるむかするのがおすすめです。
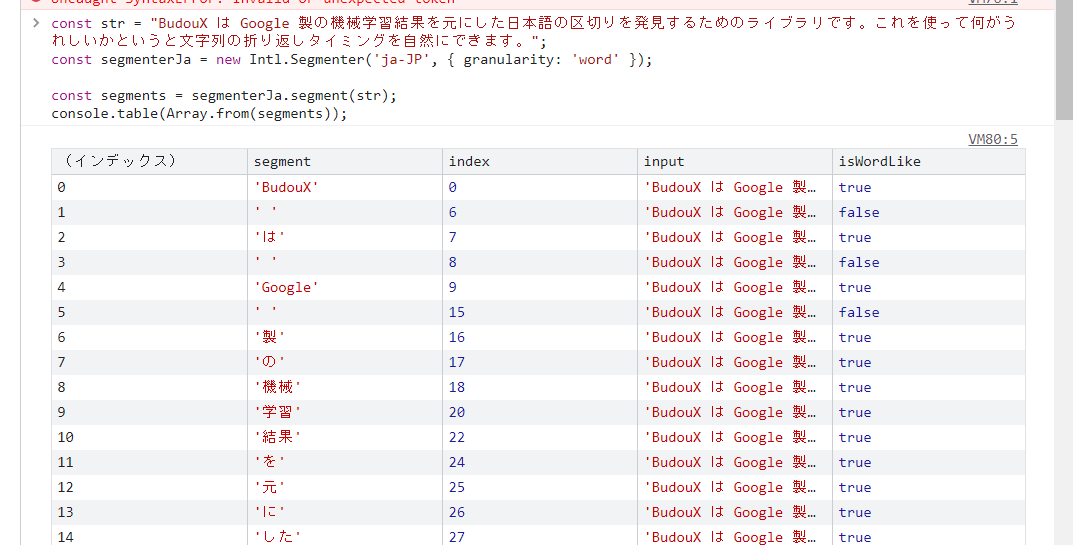
なんとなく形態素解析っぽい挙動をする BudouX ですが、形態素解析そのものが欲しいのであればブラウザ組み込みの Intl.Segmenter がおすすめです。
Intl.Segmenter – JavaScript | MDN
const str = "BudouX は Google 製の機械学習結果を元にした日本語の区切りを発見するためのライブラリです。これを使って何がうれしいかというと文字列の折り返しタイミングを自然にできます。";
const segmenterJa = new Intl.Segmenter('ja-JP', { granularity: 'word' });
const segments = segmenterJa.segment(str);
console.log(Array.from(segments));