

k-means法は任意のデータをk種類のクラスタに分割する手法です。クラスタは集まりを意味する語でクラスやグループと同じようなものです。k-means法によってクラスタリングを行った際、グループは距離で分割されます。k-means法のアルゴリズムは次です。
1.ランダムにk個のクラスタ中心を振り分ける。
2.各データと各クラスタ中心の距離を求めて、データを最も中心の近いクラスタに振り分ける。
3.振り分け直されたデータによるクラスタ毎の中心を求める。
4.2,3を繰り返す。繰り返しをやめる時は変化がなくなるか、あらかじめ定めた閾値以下の微小な変化しかしなくなった時。
数式にすれば
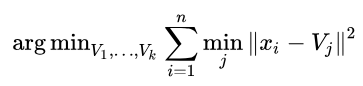
x:各データ V:各クラスタ中心
です。具体的に画像で見てみると次です。
1.ランダムにk個のクラスタ中心を振り分けます。

2.各データと各クラスタ中心の距離を求めて、データを最も中心の近いクラスタに振り分ける。
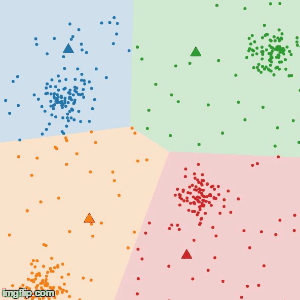
3.振り分け直されたデータによるクラスタ毎の中心を求める。
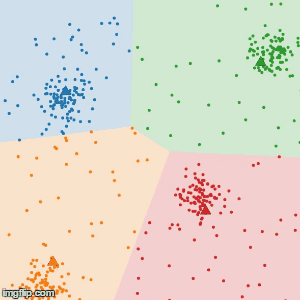
2.各データと各クラスタ中心の距離を求めて、データを最も中心の近いクラスタに振り分ける。
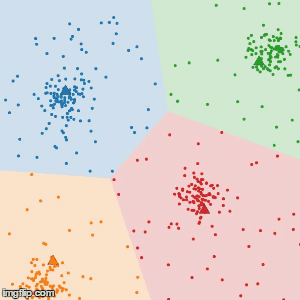
3.振り分け直されたデータによるクラスタ毎の中心を求める。
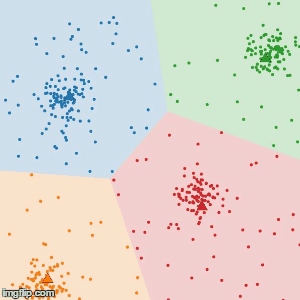
2.各データと各クラスタ中心の距離を求めて、データを最も中心の近いクラスタに振り分ける。
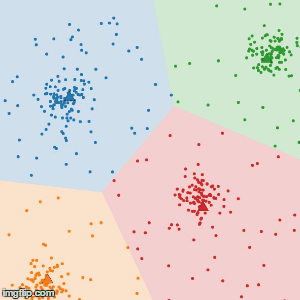
3.振り分け直されたデータによるクラスタ毎の中心を求める。
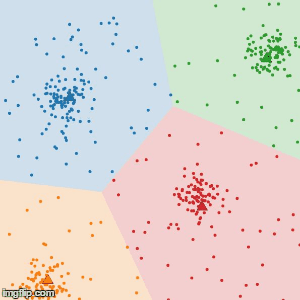
4.繰り返しをやめる。
まとめて

k-means法はクラスタに所属するデータとクラスタ中心の最大距離の近いk個のクラスタを自動生成する手法です。kは任意であり、k-mean法の使用者が任意に決定します。kを自動決定するように拡張されたx-means法という手法もあります。



