

機械学習において学習、評価に用いられる学習データは出力結果の正しさ、出力までの計算時間に大きく関わります。学習データが小さすぎれば十分な正確さを持てず、大きすぎれば無用な計算時間が大量に増え、偏れば偏った結果しか出ません。
学習データ数が増えるにつれて出力の正確さは増えます。増え方は対数に近く飽和が起きます。
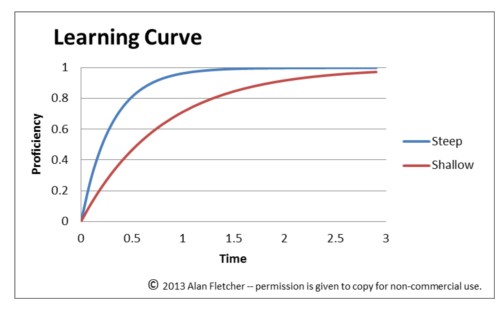
飽和している状態でさらに学習を行うのは時間の無駄です。正確さの増加量、飽和点は変数の数などのモデルの柔軟性によって大きく変わります。ディープラーニングの様な柔軟性が高いモデルを用いる場合、特に大量の学習データを用意する必要があります。近年はデータに対して自然にありえるであろう微細な加工を施すことで少ない学習データを大量の学習データをの様に扱う技術が生まれ始めています。
機械学習の実行にかかる計算時間は学習データの数と項目数に大きく左右されます。計算量はデータ数と項目数の積になりがちです。これにより組み合わせ爆発同様の事態に陥ります。単純な繰り返しによる網羅はあっという間に破綻します。
学習データの偏り方は学習データの母集団と目的の母集団のずれがバイアスとして現れます。通年の天気のデータを予測するために、夏の天気のデータのみを用いる様なものです。以前書いたアンケートのバイアスの話と同じです。


