

少し前に話題になっており、今も存在感のあるビッグデータという言葉があります。この記事ではビッグデータの解析等で役に立っている統計学の技術である主成分分析の紹介をします。
大量のデータはその大きさに違わず大量の重複した情報をはらんでいることがあります。主成分分析とは重複した情報をまとめ、計算効率よく処理することを可能にする方法です。この重複した情報には似た意味を持つ情報というのは異なる項目成れど、片方が分かればもう片方もほとんどわかるような密接な関係にある情報のことも含みます。完全に重複した情報の例にはある物体中に含まれる分子の数と原子の数、似た情報の例には身長と体重が挙げられます。主成分分析はこの重複した情報を一つの情報としてまとめる方法です。項目数を減らすことは計算量の減少に大きく貢献します。例えば、8つの選択肢のある項目が3つあった場合、すべてのパターンを網羅するには8^3=512個の処理が必要ですが、主成分分析によって項目を2つに減らした場合、8^2=64個の処理で済むことになります。単純なやり方はある項目Aとある項目Bを最小二乗法で一次式を引き、一次式がよく当てはまれば、その一次式の傾きに合わせて次元を削減、というものです。下図なんかがわかりやすいです。三項目のデータを二項目で表しています。
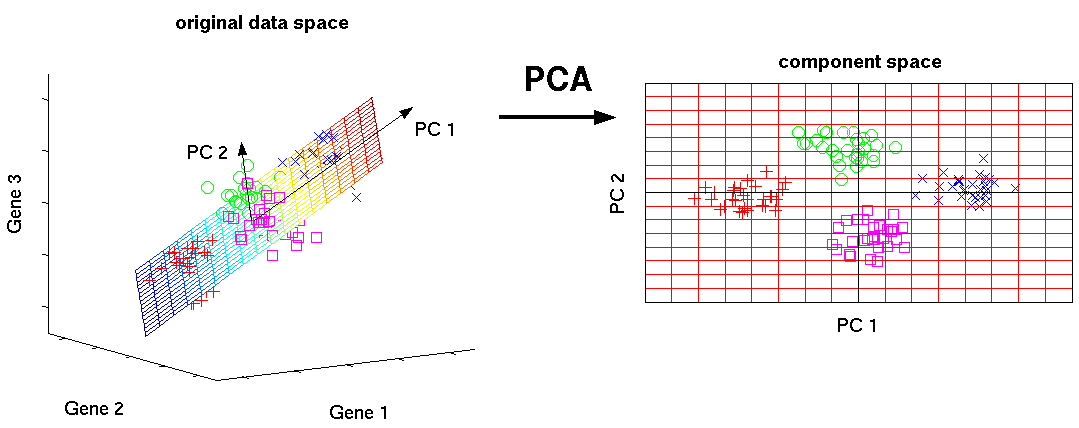
この手法の応用のために使われる関連技術には、平面でなくもっと複雑な面にまとめるカーネルやスカスカなデータは不要と判断するスパース性なんかがあります。


