


この記事の結論は、ディープラーニングは、限られた情報空間内における予測、識別がとても得意であり、学習した情報に類似のない未知の情報に対する予測、識別が不得意、ということです。(y=xという式を予測したいとき、学習データがx=0からx=100までの範囲しかないならx=1000の場合の予測は無茶苦茶になりやすい、みたいな)
近年、ディープラーニングとして多数の層に組まれたニューラルネットワーク(以下NN)が注目されています。ディープラーニングという技術はNNの延長線上にあり、利点を伸ばし、欠点を小さくしながらもNNと同じ利点、欠点を引き継いでいます。
NNは確率的場合分けによる多値分類手法といえます。ここでいう分類とはaはカテゴリAに属する、bはカテゴリBに属する、…といったものです。確率的場合分けと確率的でない場合分けの違いを述べます。たとえば、AとBを場合分けするとします。確率的場合分けはAの確率70%、Bの確率30%と一度出力し、最も高い確率はAなのでAと分類します。確率的でない場合分けは確率を介さずにAと分類します。この場合分けを行う関数が活性化関数と呼ばれます。活性化関数にはステップ関数、シグモイド関数等の関数があります。
ステップ関数
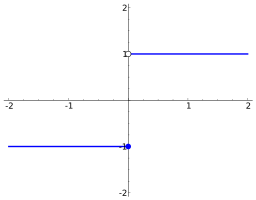
0か1かのみの関数です。縦軸が0ならばA、1ならばBといった具合です。0%、100%という確率を表してるとも言えます。
シグモイド関数
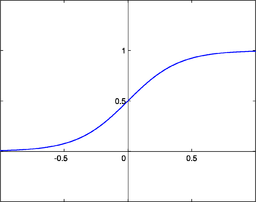
0から1までを滑らかに表す関数です。縦軸が0.3ならばAの確率30%といった具合です。このシグモイド関数のような関数を用いることで確率的場合分けを行うことができます。関数の形からわかる様にこの関数単体で可能な分類は二値分類のみです。
多値分類とは分類結果の種類が3種類以上の場合の分類のことです。先ほど紹介した活性化関数を複数介することで複数種類の分類を行うことができます。下図の黒丸一つ一つが活性化関数です。左端の入力を上からx,y,zとします。活性化関数の出力である矢印はいずれも単一の出力である同じ値のことを示しています。活性化関数の一つであるシグモイド関数は出力:1/(1+exp(ax+by+cz))となるような関数です。このa、b、cはパラメータです。
![]()
ネットワークに学習をさせるということは、あるデータがこの関数らを介してどこに分類されるか、それが正しい分類かを試し、より正しく分類できる関数になるようにパラメータを変化させることです。上図では最終出力が二つあります。この最終出力は様々です。それぞれAである確率、Bである確率の様な単なる分類結果とすることもありますし、同じ入力から全く別の二種類の情報を得ようとすることもあります。
学習データに完璧に対応したネットワークが完成した場合、学習に用いたデータと同様のデータを入力した時には正しい分類を行うことができます。ディープなNNを構成するディープラーニングで用いるモデルは柔軟なモデルであり学習データに完璧に対応したネットワークが構成されやすいです。学習を行っていないデータが入力されたときはどうなるか。ネットワークは入力されたデータが学習に用いたデータに類似したデータの場合、正しい分類を行います。一方で学習に用いたデータと類似していないデータの場合、あてずっぽうともいえる的外れな分類を行いやすいです。このためディープラーニングは、学習したデータとその近辺の予測、識別が得意、学習した情報に類似のない未知の情報に対する予測、識別が不得意、ということになります。
余談:ディープラーニングが画像認識を得意とする理由の一因は画像の変化としてありえそうなパターンである拡縮回転、光源等による規則的な色調変化を広くカバーできるためです(学習データを拡縮回転、規則的な色調変化すればそれでありえそうな異なる画像を学習したのと同じことになる。ディープラーニングは学習データを増やしても学習データに対応できる柔軟性がモデルにある)。


